
Simplifying Infrastructure - A Feynman style guide to git workflows (Part 3)
Why infrastructure needs different rules than applications (and that's perfectly fine)

I learned very early the difference between knowing the name of something and knowing something.
— Richard Feynman
In the world of software development, we throw around terms like Git Flow, GitHub Flow, and GitLab Flow as if simply knowing their names makes us experts. But do we really understand what these branching strategies actually accomplish? And more importantly, do we understand when to use each one?
Let me tell you a story about branching strategies the way Feynman might have explained physics to a curious student - by getting to the heart of what's actually happening, stripping away the jargon, and understanding the fundamental principles at work.

Let’s explore why different types of software development need fundamentally different approaches to branching and deployment. You'll understand the physics behind why infrastructure deployment behaves differently from application development, and why GitLab Flow has become my preferred approach for complex infrastructure work while application teams should absolutely use whatever works best for their specific context. This article is very AWS centric, but the same principles extrapolate to different software and infrastructure providers.
By the end, you'll have a clear mental model for choosing branching strategies based on the actual properties of what you're building, not on what's fashionable or what everyone else is doing.
This four-part series breaks down how I build Terraform CI/CD for complex shared infrastructure, in a simple way, that works in the real world:
Part 1 exposes why your current tooling is probably fighting against you:
Part 2 discussed how vanilla CI/CD pipelines can handle the most complex infrastructure deployments without specialised tools;
Part 3 (current post) looks into branching strategies, and explores my personal preference for GitLab Flow for complex infrastructure, while allowing developer teams to use whichever strategy they prefer;
Part 4 shows you the functional composed-repository pattern that scales from startup to enterprise without the complexity death spiral;
Main Insights
Different problems require different solutions: Infrastructure and applications have fundamentally different deployment physics;
GitLab Flow provides controlled energy states: Like quantum mechanics, infrastructure changes need predictable transitions between stable states;
Application teams should optimise for their specific conditions: Micro-services, monoliths, and different team sizes create different optimal strategies;
Understanding the underlying mechanics matters more than following conventions: The "why" determines the "how";
Flexibility within structure creates the best outcomes: Infrastructure needs control, applications need speed, both can coexist.
The fundamental physics of code deployment
Feynman had a gift for finding simple explanations for complex phenomena. So let's start with a simple question: what are we actually trying to accomplish with branching strategies?
At its core, a branching strategy is a system for managing energy states. In physics, particles exist in different energy states, and there are rules governing how they can transition between these states. Software development works similarly - your code exists in different states (development, staging, production), and there are rules governing how it transitions between them.
But here's where it gets interesting: different types of software have completely different physics.
Application Physics: Applications, especially micro-services, behave like independent particles. When one application changes state (gets deployed), it typically doesn't affect the energy state of other applications. They can transition independently, rapidly, and with minimal coordination;
Infrastructure Physics: Infrastructure behaves more like a complex molecular structure. When you change one component, it affects everything bonded to it. Infrastructure changes have wide-ranging effects, require careful coordination, and need stable intermediate states to prevent system collapse;
This isn't just metaphor - these are real, observable differences in how software systems behave when you deploy changes to them.
The four branching strategies: Understanding their natural habitats
Let me explain each branching strategy by describing the conditions where it naturally thrives, like Feynman might have described different types of atomic behaviour under different environmental conditions.
Git Flow: The formal laboratory
Git Flow is like conducting experiments in a formal laboratory with strict protocols. You have dedicated spaces for different types of work: a develop branch for active research, feature branches for individual experiments, release branches for preparing findings for publication, and hotfix branches for urgent corrections.
This strategy works best when:
You're working with large, coordinated teams that need clear protocols;
You're managing multiple product versions simultaneously (like maintaining different versions of scientific equipment);
Your deployment process has formal review cycles and scheduled releases;
The cost of errors is high enough to justify the additional ceremony;
The downside? All that protocol creates friction. Your development velocity decreases because every change must follow the established procedures. For many modern applications, this friction costs more than it prevents.
GitHub Flow: The agile workshop
GitHub Flow strips away most of the formal protocol. You have one main branch that represents production, and you create short-lived feature branches for each change. When the feature is ready, it goes directly to production.
This works beautifully when:
You're working with smaller, more agile teams;
Your deployment process is automated and reliable;
Your system can handle continuous deployment without breaking;
The cost of occasional errors is lower than the cost of slow deployment;
The simplicity is its strength, but also its weakness for complex shared infrastructure. Without intermediate staging, you're betting that your testing and automation are good enough to catch problems before they reach production.
Trunk-based development: The high-energy accelerator
Trunk-based development is like running a particle accelerator - everything happens in one high-energy environment with very short interaction times. Developers create very short-lived feature branches (measured in hours or days, not weeks) which then gets merged to the main trunk.
This requires extraordinary discipline and infrastructure:
Comprehensive automated testing that can catch problems instantly;
Feature flags to control what gets exposed to users;
Experienced teams that can slice features into very small, safe increments;
Monitoring systems that can detect and rollback problems immediately;
When it works, it's incredibly powerful. Teams can deploy multiple times per day with confidence. But it requires a level of technical sophistication that many teams haven't reached.
GitLab Flow: The controlled reactor
GitLab Flow is my preferred approach for complex infrastructure, and here's why: it behaves like a controlled nuclear reactor. You have multiple stable energy states (development, staging, production), and you control the rate of transitions between them.
Unlike GitHub Flow, you don't go directly from feature branch to production. Changes first prove themselves in the development environment, then graduate to staging, and finally to production. Each transition is controlled and observable.
This controlled approach prevents the infrastructure equivalent of chain reactions - cascading failures that happen when poorly tested infrastructure changes interact in unexpected ways.
Why infrastructure needs different rules
Here's the key insight that many people miss: infrastructure and applications have fundamentally different failure modes.
Application Failure Characteristics:
Typically isolated to a single service or feature;
Can often be rolled back quickly;
Users might not notice if one micro-service is temporarily unavailable;
Testing can catch most functional problems;
Changes usually have predictable effects;
Infrastructure Failure Characteristics:
Can affect multiple applications and services simultaneously;
May require complex recovery procedures;
Failures often cascade through dependent systems;
Integration problems are harder to test comprehensively;
Changes can have subtle, delayed effects;
Let me give you a concrete example. If you deploy a bug in your shopping cart micro-service, customers might not be able to complete purchases for a few minutes while you roll back. That's bad, but it's contained.
If you deploy a mis-configured network firewall rule, you might break communication between all your services across all environments. If you delete a key piece of infrastructure, recovery isn't just rolling back - you might need to coordinate fixes across multiple systems while your entire platform is down.
This difference in failure physics is why I use GitLab Flow for infrastructure deployment. The additional staging environments act like safety valves - they give you places to observe how changes behave under production-like conditions before they affect your actual production environment.
My infrastructure GitLab Flow implementation
For complex infrastructure deployment, I use a variation of GitLab Flow that looks like this, at its simplest form:
Main Branch: Points to production AWS accounts. Changes here affect real user-facing infrastructure. Every merge to main triggers deployment to production environments, but only after passing through the development pipeline;
Development Branch: Points to development AWS accounts that mirror production topology (at a smaller and simpler scale) but use separate resources. This is where infrastructure changes prove themselves before graduating to production;
Feature Branches: Created from development for individual infrastructure changes. These are where engineers experiment with new configurations, test integration with existing systems, and validate that their changes work as expected;
This approach is pinned in the "apply-before-merge" pattern on feature branches. Instead of just running Terraform plan to see what would change, we actually apply the changes to development environments directly from the feature branch. This means we're testing the real behaviour of infrastructure changes, not just their theoretical effects.
Here's how a typical infrastructure change flows:
Feature Development: Engineer creates a feature branch from development to work on, say, a new Transit Gateway configuration;
Real Environment Testing: The feature branch pipeline actually deploys the Transit Gateway to development AWS accounts, allowing real testing of connectivity, routing, and integration;
Development Integration: Once validated, the feature branch merges to development, ensuring all infrastructure changes work together;
Production Promotion: After thorough testing in development, changes merge to main and deploy to production (in here we “merge-before-apply”);
The diagram below shows the application of this branching strategy as described:
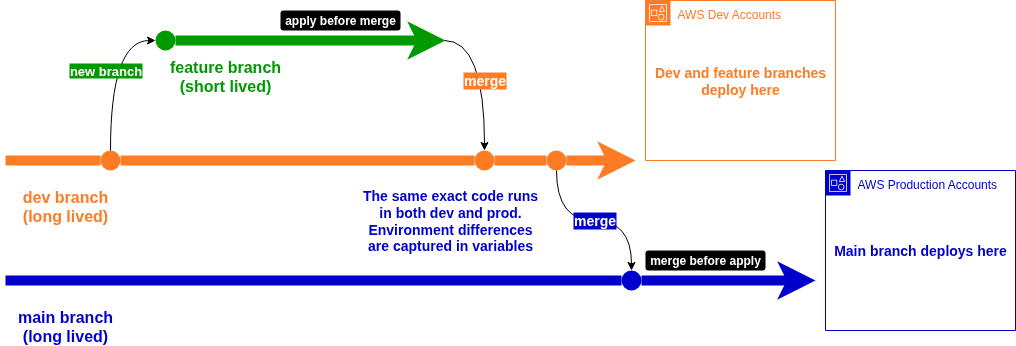
This process assumes your platform team is relatively small and centralised with clear communication lines, preventing concurrent changes to the same Terraform stack or module / CICD sub-pipeline. For infrastructure, this controlled approach prevents the coordination chaos that happens when multiple teams simultaneously change shared foundations.
Note: I recommend reading Terramate’s excellent blog post for a better understanding of “apply before merge” and “merge-before-apply”.
Application teams should choose their own branching strategy
While I'm opinionated about infrastructure branching strategies, I'm completely flexible about what application development teams should use. And this flexibility isn't laziness - it's based on understanding that different types of applications have different optimal strategies.
Micro-services Teams often thrive with GitHub Flow. Their applications have isolated failure domains, comprehensive testing, and benefit from rapid deployment cycles. The simplicity of GitHub Flow matches the independence of their deployments.
Complex Application Teams managing tightly integrated systems might benefit from Git Flow's more structured approach, especially if they coordinate releases across multiple components or need to maintain multiple versions simultaneously.
High-Velocity Teams with excellent testing discipline and monitoring capabilities might use Trunk-Based Development to achieve multiple deployments per day.
The key insight is that application teams operate in their own environment with their own constraints, risk tolerances, and velocity requirements. They should optimise for their specific conditions rather than following infrastructure patterns that don't match their physics.
Practical implementation wisdom
Feynman once said, "It doesn't matter how beautiful your theory is, it doesn't matter how smart you are. If it doesn't agree with the experiment, it's wrong." The same principle applies to branching strategies.
I've observed teams struggle with complex branching strategies that looked perfect on paper but broke down under the pressure of real development work. I've also seen teams succeed with strategies that seemed too simple for their complex systems.
The key is understanding your actual constraints:
How many people are working on shared code?
What's the blast radius of typical changes?
How quickly do you need to respond to problems?
What's your testing and monitoring capability?
How much coordination overhead can your team handle?
In summary, this is what I do and recommend:
For complex shared Infrastructure repositories: Use GitLab Flow with apply-before-merge on feature branches, and merge-before-apply when promoting to main. The additional safety is worth the coordination overhead when changes affect shared systems;
For application repositories: Let teams choose based on their specific constraints, but provide guidance on the trade-offs. Most teams benefit from starting simple (GitHub Flow) and adding complexity only if they hit specific problems;
Your branching strategy should serve your deployment physics, not the other way around. And if you understand the physics, you can choose the right strategy for each type of work you're doing - even if that means using different strategies for different repositories within the same organisation.
Surely you must be joking Mr. Feynman… That's not an inconsistency. That's engineering.
Next up: Part 4 reveals the functional mono-repo pattern that organises this approach for maximum maintainability while eliminating coordination overhead between infrastructure domains.
I invite you to subscribe to my blog, and to read a few of my favourite case-studies describing how some of my clients achieved success in their high-stakes technology projects, using the very same approach described.
Have a great day!
João